













For decades, companies have chased the goal of providing direct access to data. IT teams have worked hard to centralize data and provide analytics and reporting needs back to the business units. However, IT was bombarded with report requests, leaving the company unhappy with the pace of questions being answered. IT was a bottleneck in creating reports. The solution was to give business units direct access to data to answer their own analytics needs so they could “self-service.”
Problems with self-service
While self-service data seemed like a good solution, it led to a slew of other problems. It created data silos. It caused duplications and reporting sprawl across the company. It created confusion on which metric to use, and bad business decisions were made on incorrect data. It was hard to know the lineage of where calculations came from. Storage and costs doubled (or worse). Trust in data eroded.
Self-service is more complicated than it looks. We’ve seen multiple companies with several copies of the same customer data, and several groups would claim they “own” customer data, which is a different problem and conversation. However, if you asked each group to calculate monthly sales, the numbers would all be substantially different. The fundamental challenge is that “self-service” assumes that every data consumer can derive the right conclusions from data, given all its complexity, including definitions, edge cases, nuances, quality issues, or even defining what is “right.” Those challenges could look like this:
- Differing views on what set of actions constitutes a “sale”
- Forgetting to include or exclude a set of orders from a sales channel not stored in the primary point-of-sale system table
- Failing to filter out certain general-ledger account transactions that were part of a special project
- Knowing a customer type indicated by a combination of fields and scenarios
There are costs to all of these challenges; in fact, Experian data quality research shows bad data can negatively impact revenue by 12%.
Start with a data culture
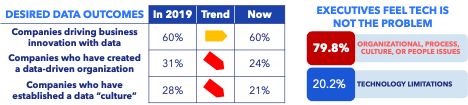
The solution to this complex problem is not to revert to old ways of working. There is not one solution, and surveys show it’s not primarily a technology problem. A multi-pronged approach that leans heavily into creating a new culture around data to modify the ways of thinking and behaviors so companies can maximize the outcomes and potential from their data.
How can companies create a data culture?
Act like data is a first-class business asset
Data is not just operational system exhaust that’s combined into a soup to feed corporate answers. Data is a business asset capable of generating new value, new products, new services, and better experiences. It means data deserves the same investment, focus, and innovation as other business capabilities, making it central to all business ventures to ask, “What data are we going to get from this?” It deserves the same level of product management and quality control as applied to core products and services. However, recognizing this and acting on it are separate things.
Taking action requires establishing a new culture wrapped around data. Consider these key steps to begin your journey:
- Focus and energy is needed from the top down as executives need to help paint and push the data vision that helps the org march together
- Clearly define data ownership, its meaning, and who owns what responsibilities
- Consider data producers and consumers, and proactively evolve the fabric of technologies they use to communicate, collaborate, and create data value
- Proactively evolve this fabric to bring new capabilities for consumers and producers to create value faster without sacrificing quality
- Data producers must prioritize and evolve their data products to create and meet the demand
- Re-evaluate people structures and processes supporting data
Make data discoverability a priority
Putting info on a bunch of tables and columns into a spreadsheet, sending it in a message, and calling it a day is not data discoverability nor adequate metadata management. Just as User Stories in Agile development were meant as reminders to have a conversation with someone, metadata should be a reminder to have a conversation with someone who knows the data. It needs to be alive and intuitive. Data consumers and producers must have conversations to understand needs, priorities, and nuances. They also need a shared language to describe business terms and understand how different data relates to them.
Enter the Data Catalog (a software product that addresses data discoverability, metadata management, and lineage tracking). Today, data catalogs are no longer an optional component. Data-driven companies need a data catalog for data consumers to search for available data products and be encouraged to reduce duplication through reuse and modification. Through the catalog, consumers should be able to answer lineage questions such as “Where did this data come from?” and be able to contact data owners to facilitate a conversation.
However, having a data catalog by itself is not enough. The data catalog needs to be wrapped with automation, governance processes, and clear expectations to keep the metadata up to date, including adherence metrics and accountability. It involves creating and managing a business glossary and then linking and relating those terms back to specific data fields. It also assumes consumers are aware a data catalog exists and understand how to use it…
Proactively drive a data literacy program
Transforming the data culture doesn’t happen overnight. It takes active encouragement and convincing of executives, data consumers, and producers on the value of data and how to use it properly. It takes educating them on opportunity, culture, tools, literacy, processes, governance, regulations, and more.
People need both data awareness and clear steps to advance their maturity:
- If employees want access to data, they should complete the first level of the data literacy training program and be certified
- If employees want to make changes to the data, ensure they go through the second level explaining the DataOps steps and make sure they can demonstrate their understanding
- Create starter projects for people to see examples using recorded short videos and walk-throughs.
- Bring forth architecture and software proposal changes to evolve the data fabric
- Create a shared communication space (using Slack, Teams, etc.) for others to ask questions and bounce ideas off one another
- As data products are released and modified, share updates with producers and consumers so they might capitalize on changes
- Create opportunities for people to present and share findings & learnings with each other
- Coach people and then get them to talk with each other to break down data barriers
It starts with one
It takes active energy and a willingness to overcome the initial friction to harvest the fruit from a data-driven culture, but it’s worth it. The potential value is too great for companies not to act. Democratizing data value creation across the organization is how data value scales; it’s not “shadow IT”; it’s “embedded IT” and must be embraced.
First, everyone must align with the vision, know what it takes and why, and have the tools & skills to move. Then, companies can finally head down the path toward true self-service.
But… it starts with a leader and a vision.





